Carry your business information era and technique at Turn into 2021.
Final week, I wrote an research of Praise Is Sufficient, a paper via scientists at DeepMind. Because the identify suggests, the researchers hypothesize that the proper present is all you want to create the skills related to intelligence, similar to belief, motor purposes, and language.
That is by contrast with AI programs that attempt to mirror explicit purposes of herbal intelligence similar to classifying pictures, navigating bodily environments, or finishing sentences.
The researchers cross so far as suggesting that with well-defined present, a fancy surroundings, and the proper reinforcement studying set of rules, we can achieve synthetic common intelligence, the type of problem-solving and cognitive skills present in people and, to a lesser stage, in animals.
The thing and the paper precipitated a heated debate on social media, with reactions going from complete toughen of the speculation to outright rejection. After all, all sides make legitimate claims. However the fact lies someplace within the center. Herbal evolution is evidence that the present speculation is scientifically legitimate. However imposing the natural present means to achieve human-level intelligence has some very hefty necessities.
On this put up, I’ll attempt to disambiguate in easy phrases the place the road between idea and apply stands.
Herbal variety
Of their paper, the DeepMind scientists provide the next speculation: “Intelligence, and its related skills, can also be understood as subserving the maximisation of present via an agent performing in its surroundings.”
Medical proof helps this declare.
People and animals owe their intelligence to a very easy regulation: herbal variety. I’m now not knowledgeable at the subject, however I recommend studying The Blind Watchmaker via biologist Richard Dawkins, which gives an overly obtainable account of the way evolution has resulted in all kinds of existence and intelligence on out planet.
In a nutshell, nature offers choice to lifeforms which can be higher are compatible to continue to exist of their environments. The ones that may face up to demanding situations posed via the surroundings (climate, shortage of meals, and so forth.) and different lifeforms (predators, viruses, and so forth.) will continue to exist, reproduce, and go on their genes to the following era. Those who don’t get eradicated.
In keeping with Dawkins, “In nature, the standard deciding on agent is direct, stark and easy. It’s the grim reaper. After all, the causes for survival are anything else however easy — because of this herbal variety can increase animals and crops of such bold complexity. However there’s something very crude and easy about dying itself. And nonrandom dying is all it takes to make a choice phenotypes, and therefore the genes that they comprise, in nature.”
However how do other lifeforms emerge? Each newly born organism inherits the genes of its father or mother(s). However not like the virtual global, copying in natural existence isn’t an actual factor. Subsequently, offspring frequently go through mutations, small adjustments to their genes that may have an enormous affect throughout generations. Those mutations could have a easy impact, similar to a small trade in muscle texture or pores and skin colour. However they may be able to additionally develop into the core for creating new organs (e.g., lungs, kidneys, eyes), or dropping previous ones (e.g., tail, gills).
If those mutations lend a hand enhance the probabilities of the organism’s survival (e.g., higher camouflage or sooner pace), they’ll be preserved and handed directly to long run generations, the place additional mutations would possibly fortify them. For instance, the primary organism that evolved the facility to parse gentle knowledge had a huge benefit over the entire others that didn’t, despite the fact that its talent to look used to be now not similar to that of animals and people these days. This benefit enabled it to higher continue to exist and reproduce. As its descendants reproduced, the ones whose mutations progressed their sight outmatched and outlived their friends. Thru 1000’s (or hundreds of thousands) of generations, those adjustments led to a fancy organ similar to the attention.
The straightforward mechanisms of mutation and herbal variety has been sufficient to offer upward thrust to the entire other lifeforms that we see on Earth, from micro organism to crops, fish, birds, amphibians, and mammals.
The similar self-reinforcing mechanism has additionally created the mind and its related wonders. In her guide Sense of right and wrong: The Starting place of Ethical Instinct, scientist Patricia Churchland explores how herbal variety resulted in the improvement of the cortex, the principle a part of the mind that provides mammals the facility to be informed from their surroundings. The evolution of the cortex has enabled mammals to expand social conduct and learn how to are living in herds, prides, troops, and tribes. In people, the evolution of the cortex has given upward thrust to advanced cognitive schools, the capability to expand wealthy languages, and the facility to ascertain social norms.
Subsequently, when you believe survival as without equal present, the principle speculation that DeepMind’s scientists make is scientifically sound. Then again, in the case of imposing this rule, issues get very sophisticated.
Reinforcement studying and synthetic common intelligence
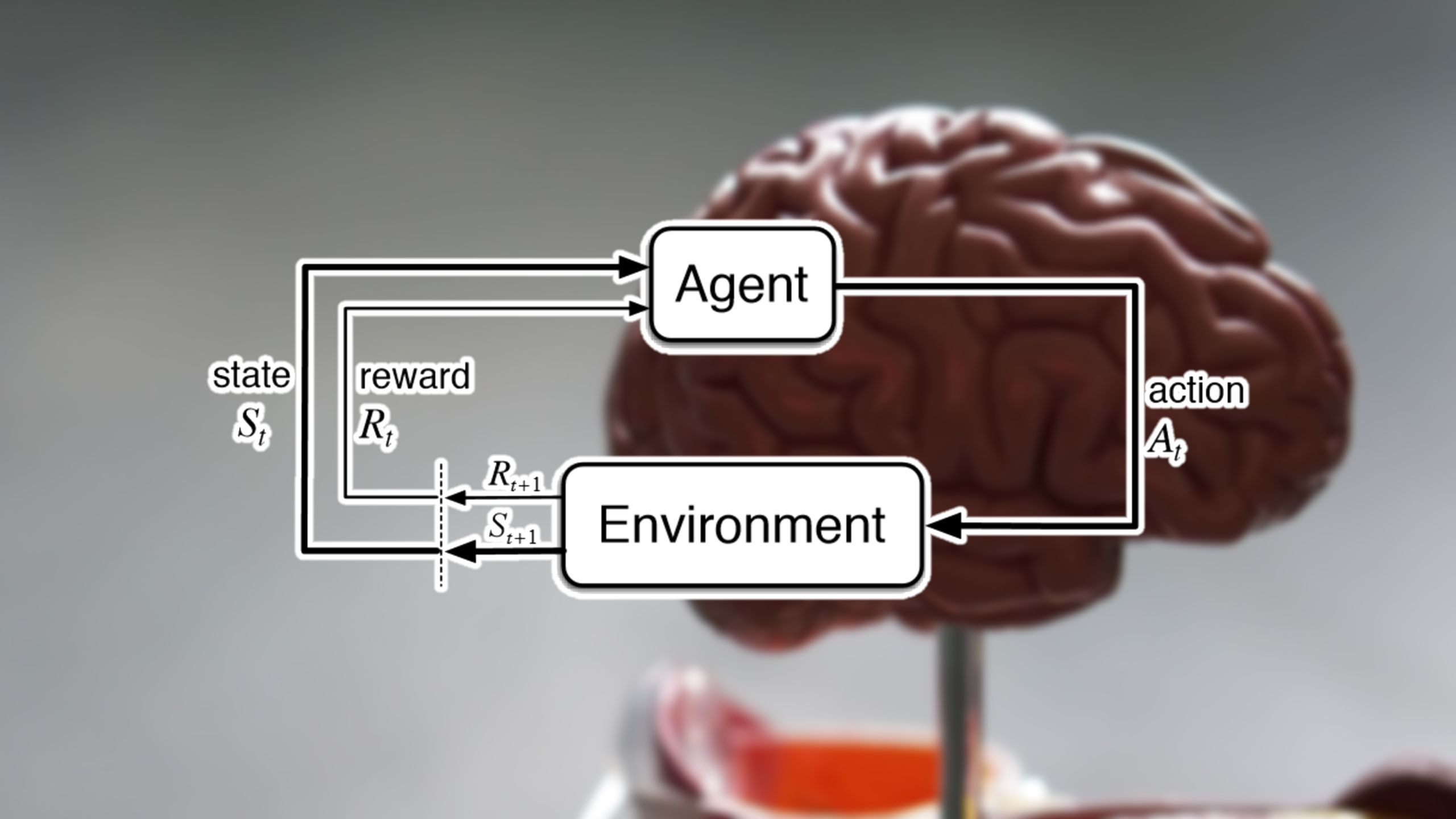
Of their paper, DeepMind’s scientists make the declare that the present speculation can also be carried out with reinforcement studying algorithms, a department of AI through which an agent step by step develops its conduct via interacting with its surroundings. A reinforcement studying agent begins via making random movements. In line with how the ones movements align with the objectives it is making an attempt to succeed in, the agent receives rewards. Throughout many episodes, the agent learns to expand sequences of movements that maximize its present in its surroundings.
In keeping with the DeepMind scientists, “A sufficiently tough and common reinforcement studying agent might in the end give upward thrust to intelligence and its related skills. In different phrases, if an agent can frequently alter its behaviour so to enhance its cumulative present, then any skills which can be again and again demanded via its surroundings should in the end be produced within the agent’s behaviour.”
In an on-line debate in December, laptop scientist Richard Sutton, some of the paper’s co-authors, stated, “Reinforcement studying is the primary computational idea of intelligence… In reinforcement studying, the objective is to maximise an arbitrary present sign.”
DeepMind has a large number of revel in to end up this declare. They’ve already evolved reinforcement studying brokers that may outmatch people in Pass, chess, Atari, StarCraft, and different video games. They’ve additionally evolved reinforcement studying fashions to make growth in probably the most most intricate issues of science.
The scientists additional wrote of their paper, “In keeping with our speculation, common intelligence can as a substitute be understood as, and carried out via, maximising a unique present in one, advanced surroundings [emphasis mine].”
That is the place speculation separates from apply. The key phrase this is “advanced.” The environments that DeepMind (and its quasi-rival OpenAI) have to this point explored with reinforcement studying don’t seem to be just about as advanced because the bodily global. They usually nonetheless required the monetary backing and huge computational assets of very rich tech firms. In some instances, they nonetheless needed to dumb down the environments to hurry up the learning in their reinforcement studying fashions and lower down the prices. In others, they needed to redesign the present to verify the RL brokers didn’t get caught the flawed native optimal.
(It’s value noting that the scientists do recognize of their paper that they may be able to’t be offering “theoretical ensure at the pattern potency of reinforcement studying brokers.”)
Now, consider what it might take to make use of reinforcement studying to duplicate evolution and achieve human-level intelligence. First you could possibly desire a simulation of the sector. However at what point would you simulate the sector? My wager is that anything else in need of quantum scale could be faulty. And we don’t have a fragment of the compute energy had to create quantum-scale simulations of the sector.
Let’s say we did have the compute energy to create this sort of simulation. Lets get started at round four billion years in the past, when the primary lifeforms emerged. You would have to have an actual illustration of the state of Earth on the time. We’d want to know the preliminary state of our surroundings on the time. And we nonetheless don’t have a certain idea on that.
An alternate could be to create a shortcut and get started from, say, eight million years in the past, when our monkey ancestors nonetheless lived on earth. This would chop down the time of coaching, however we’d have a a lot more advanced preliminary state to start out from. At the moment, there have been hundreds of thousands of various lifeforms on Earth, and so they had been carefully interrelated. They developed in combination. Taking any of them out of the equation can have an enormous affect at the process the simulation.
Subsequently, you principally have two key issues: compute energy and preliminary state. The additional you return in time, the extra compute energy you’ll want to run the simulation. Then again, the additional you progress ahead, the extra advanced your preliminary state shall be. And evolution has created all kinds of clever and non-intelligent lifeforms and ensuring that shall we reproduce the precise steps that resulted in human intelligence with none steering and solely thru present is a difficult wager.

Above: Symbol credit score: Depositphotos
Many will say that you just don’t want an actual simulation of the sector and also you solely want to approximate the issue area through which your reinforcement studying agent desires to function in.
For instance, of their paper, the scientists point out the instance of a house-cleaning robotic: “To ensure that a kitchen robotic to maximize cleanliness, it should probably have skills of belief (to tell apart blank and grimy utensils), wisdom (to grasp utensils), motor keep an eye on (to govern utensils), reminiscence (to recall places of utensils), language (to expect long run mess from discussion), and social intelligence (to inspire babies to make much less mess). A behaviour that maximises cleanliness should subsequently yield these kinds of skills in carrier of that singular objective.”
This commentary is right, however downplays the complexities of our surroundings. Kitchens had been created via people. As an example, the form of drawer handles, doorknobs, flooring, cabinets, partitions, tables, and the entirety you notice in a kitchen has been optimized for the sensorimotor purposes of people. Subsequently, a robotic that might need to paintings in such an atmosphere would want to expand sensorimotor talents which can be very similar to the ones of people. You’ll create shortcuts, similar to warding off the complexities of bipedal strolling or arms with arms and joints. However then, there could be incongruencies between the robotic and the people who shall be the usage of the kitchens. Many situations that might be simple to deal with for a human (strolling over an overturned chair) would develop into prohibitive for the robotic.
Additionally, different talents, similar to language, will require much more identical infrastructure between the robotic and the people who would proportion the surroundings. Clever brokers should be capable to expand summary psychological fashions of one another to cooperate or compete in a shared surroundings. Language omits many necessary main points, similar to sensory revel in, objectives, wishes. We fill within the gaps with our intuitive and aware wisdom of our interlocutor’s psychological state. We would possibly make flawed assumptions, however the ones are the exceptions, now not the norm.
And in spite of everything, creating a perception of “cleanliness” as a present may be very sophisticated as a result of it is vitally tightly related to human wisdom, existence, and objectives. For instance, putting off each and every piece of meals from the kitchen would indubitably make it cleaner, however would the people the usage of the kitchen be at liberty about it?
A robotic that has been optimized for “cleanliness” would have a difficult time co-existing and cooperating with dwelling beings which were optimized for survival.
Right here, you’ll be able to take shortcuts once more via developing hierarchical objectives, equipping the robotic and its reinforcement studying fashions with prior wisdom, and the usage of human comments to persuade it in the proper path. This is able to lend a hand so much in making it more straightforward for the robotic to grasp and have interaction with people and human-designed environments. However then you could possibly be dishonest at the reward-only means. And the mere undeniable fact that your robotic agent begins with predesigned limbs and image-capturing and sound-emitting gadgets is itself the combination of prior wisdom.
In idea, present solely is sufficient for any roughly intelligence. However in apply, there’s a tradeoff between surroundings complexity, present design, and agent design.
Someday, we may be able to reach a degree of computing energy that can make it conceivable to achieve common intelligence thru natural present and reinforcement studying. However in the meanwhile, what works is hybrid approaches that contain studying and sophisticated engineering of rewards and AI agent architectures.
Ben Dickson is a instrument engineer and the founding father of TechTalks. He writes about era, trade, and politics.
This tale at the start seemed on Bdtechtalks.com. Copyright 2021
VentureBeat
VentureBeat’s challenge is to be a virtual the city sq. for technical decision-makers to realize wisdom about transformative era and transact. Our website delivers very important knowledge on information applied sciences and techniques to lead you as you lead your organizations. We invite you to develop into a member of our group, to get admission to:
- up-to-date knowledge at the topics of hobby to you
- our newsletters
- gated thought-leader content material and discounted get admission to to our prized occasions, similar to Turn into 2021: Be informed Extra
- networking options, and extra


