These days, Google’s Open Photographs corpus for laptop imaginative and prescient duties were given a spice up with new visible relationships, human motion annotations, and image-level labels, in addition to a brand new type of multimodal annotations referred to as localized narratives. Google says this remaining addition may create “possible avenues of study” for learning how other folks describe pictures, which might result in interface design insights (and next enhancements) throughout internet, desktop, and cellular apps.
In 2016, Google offered Open Photographs, a knowledge set of hundreds of thousands of classified pictures spanning hundreds of object classes. Main updates arrived in 2018 and 2019, bringing with them 15.four million bounding-boxes for 600 object classes and segmentation mask (which mark the description of gadgets) for two.eight million object circumstances in 350 classes.
“In conjunction with the knowledge set itself, the related Open Photographs demanding situations have spurred the most recent advances in object detection, example segmentation, and visible dating detection,” wrote Jordi Pont-Tuset, a analysis scientist at Google Analysis. “Open Photographs is the most important annotated picture information set in lots of regards, to be used in coaching the most recent deep convolutional neural networks for laptop imaginative and prescient duties.”
As Pont-Tuset explains, one of the vital motivations in the back of localized narratives is to leverage the relationship between imaginative and prescient and language, which is most often completed by way of picture captioning (i.e., pictures paired with written descriptions in their content material). However picture captioning lacks visible “grounding.” To mitigate this, some researchers have drawn bounding bins for the nouns in captions after the truth — against this to localized narratives, the place each and every phrase within the description is grounded.
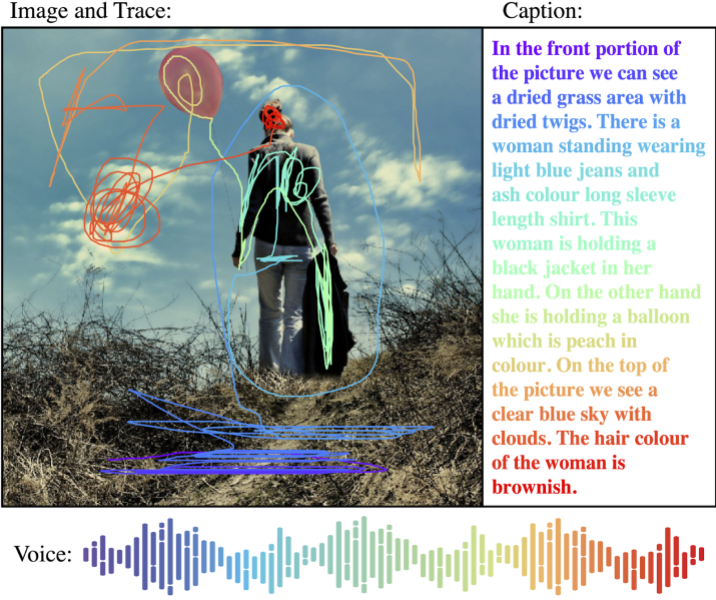

The localized narratives in Open Photographs have been generated through annotators who supplied spoken descriptions of pictures whilst soaring over areas they have been describing with a pc mouse. The annotators manually transcribed their description, and then Google researchers aligned it with computerized speech transcriptions, making sure that the speech, textual content, and mouse hint have been proper and synchronized.
“Talking and pointing concurrently are very intuitive, which allowed us to present the annotators very obscure directions concerning the job,” defined Pont-Tuset. “[This latest version of] Open Photographs is a vital qualitative and quantitative step towards bettering the unified annotations for picture classification, object detection, visible dating detection, and example segmentation … [we] hope that [it] will additional stimulate development towards authentic scene working out.”
Open Photographs is freely to be had. Consistent with Google, Open Photographs now has nine million pictures annotated with 36 million image-level labels, 15.eight million bounding bins, 2.eight million example segmentations, 391,000 visible relationships, and 59.nine million human-verified image-level labels in just about 20,000 classes.


