People don’t have any hassle spotting items and reasoning about their behaviors — it’s on the core in their cognitive construction. At the same time as youngsters, they staff segments into items according to movement and use ideas of object permanence, solidity, and continuity to provide an explanation for what has took place and believe what would occur in different eventualities. Impressed via this, a crew of researchers hailing from the MIT-IBM Watson AI Lab, MIT’s Laptop Science and Synthetic Intelligence Laboratory, Alphabet’s DeepMind, and Harvard College sought to simplify the issue of visible reputation via introducing a benchmark — CoLlision Occasions for Video REpresentation and Reasoning (CLEVRER) — that pulls on inspirations from developmental psychology.
CLEVRER comprises over 20,000 Five-second movies of colliding items (3 shapes of 2 fabrics and 8 colours) generated via a physics engine and greater than 300,000 questions and solutions, all that specialize in 4 components of logical reasoning: descriptive (e.g., “what colour”), explanatory (“what’s answerable for”), predictive (“what’s going to occur subsequent”), and counterfactual (“what if”). It comes with ground-truth movement strains and match histories for every object within the movies, and with practical methods representing underlying common sense that pair with every query.
The researchers analyzed CLEVRER to spot the weather vital to excel now not handiest on the descriptive questions, which cutting-edge visible reasoning fashions can do, however on the explanatory, predictive, and counterfactual questions as neatly. They discovered 3 components — reputation of the items and occasions within the movies, modeling the dynamics and causal family members between the items and occasions, and working out of the symbolic common sense in the back of the questions — to be a very powerful, and so they evolved a fashion — Neuro-Symbolic Dynamic Reasoning (NS-DR) — that explicitly joined them in combination by means of a illustration.
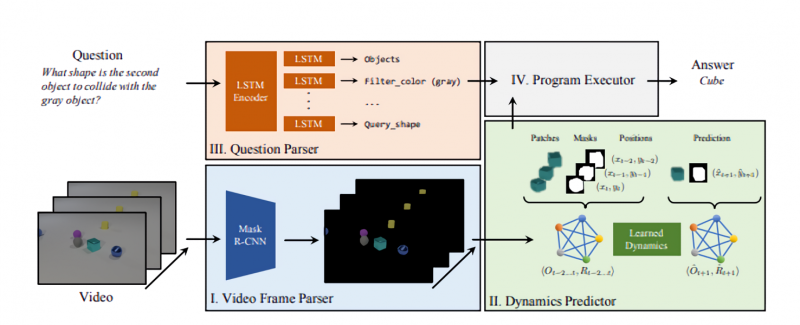
NS-DR is in truth 4 fashions in a single: a video body parser, a neural dynamics predictor, a query parser, and a program executor. Given an enter video, the video body parser detects items within the scene and extracts each their strains and attributes (i.e. place, colour, form, subject material). Those shape an summary illustration of the video, which is shipped to the neural dynamics predictor to look forward to the motions and collisions of the items. The query parser receives the enter query to procure a practical program representing its common sense. Then the symbolic program executor runs this system at the dynamic scene and outputs a solution.

The crew stories that their fashion completed 88.1% accuracy when the query parser used to be skilled underneath 1,000 methods, outperforming different baseline fashions. On explanatory, predictive, and counterfactual questions, it controlled a “extra important” acquire.
“NS-DR [incorporates a] dynamics planner into the visible reasoning activity, which at once allows predictions of unobserved movement and occasions, and allows the fashion for the predictive and counterfactual duties,” famous the researchers. “This means that dynamics making plans has nice possible for language-grounded visible reasoning duties, and NS-DR takes a initial step towards this course. 2nd, symbolic illustration supplies a formidable not unusual floor for imaginative and prescient, language, dynamics, and causality. Through design, it empowers the fashion to explicitly seize the compositionality in the back of the video’s causal construction and the query common sense.”
The researchers concede that even supposing the volume of information required for coaching is somewhat minimum, it’s onerous to come back via in real-world programs. Moreover, NS-DR’s efficiency reduced on duties that required long-term dynamics prediction, such because the counterfactual questions, which they are saying suggests the desire for a greater dynamics fashion able to producing extra strong and correct trajectories.


